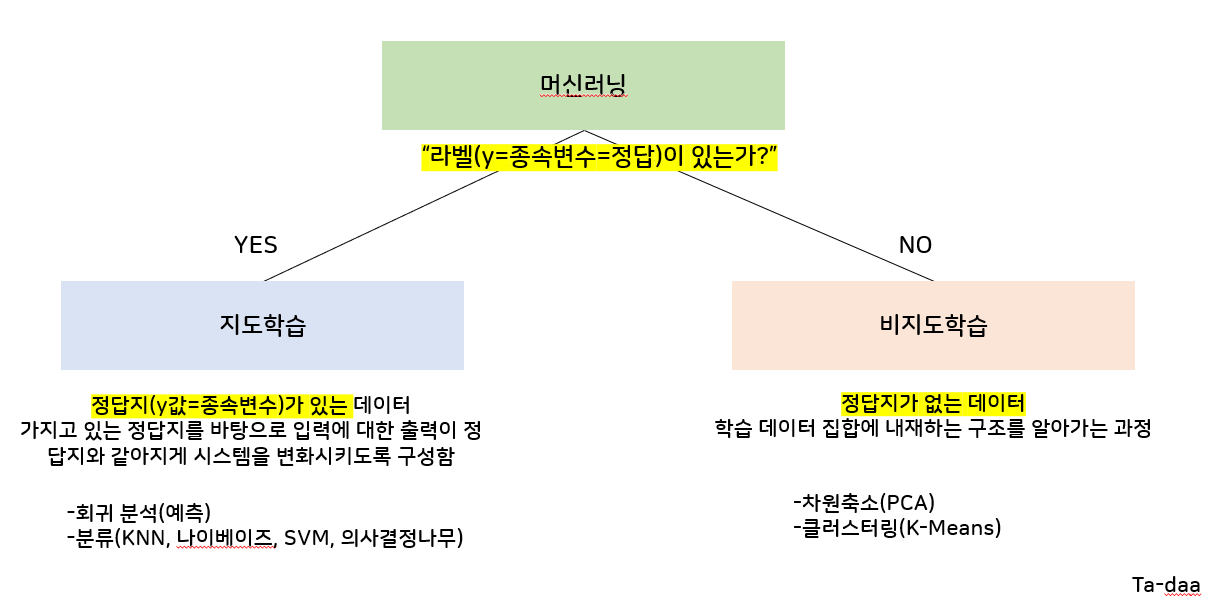
지도학습
정답이 있는 데이터를 가지고 학습하는 방식
입력과 출력이 짝지어져 있는 데이터를 사용
새로운 입력이 들어오면 정답을 예측
비지도학습
답이 없는 데이터를 가지고 숨은 패턴을 찾는 방식
모델은 입력만 보고 데이터 구조나 군집을 스스로 학습
장단점
지도학습
장점 - 예측 성능이 좋음
단점 - 많은 라벨링 데이터 필요
비지도학습
장점 - 라벨 필요 X
단점 - 정답이 없어 성능 평가가 어려움
KNN
어떤 데이터가 들어왔을 때 가장 가까운 k개의 이웃 데이터을 찾아서
그 이웃들이 속한 라벨에 따라 분류하거나 값을 예측하는 방식
KNN의 과정
1. 특별한 학습 과정 없음 -> 데이터를 그냥 저장
2. 새 데이터가 들어오면 거리 계산
3. 가장 가까운 k개를 찾음
4. 다수결 또는 평균으로 결과를 결정
KKN의 장단점
장점
직관적이고 이해 쉬움
작은 데이터셋에서는 잘 작동
단점
데이터가 많아지면 계산량 ↑
차원이 커지면 성능 저하
K-meansClustering
데이터에 라벨이 없는 상황에서 데이터를 k개의 그룹으로 자동 분류
각 그룹의 중심을 찾고 데이터를 가장 가까운 중심에 배정
장점
라벨이 없어도 그룹을 나눌 수 있음
간단하고 빠름
단점
k를 직접 정해야 함
복잡한 모양의 데이터에는 성능이 떨어짐

K-meansClustering의 과정
1.몇 개(K)의 덩어리로 군집화할지 정한 후, K 만큼 중심점을 정한다.
2. 각 점마다 가장 가까운 군집을 정한다.
3. 군집을 이동한다.
4. 이 과정을 계속 반복해서 더 이상 서로 매핑되지 않을 때까지 반복한다.
5. 더 이상 이동이 없어지면 군집화가 완료되고 K개의 군집이 완성된다.